| Collaborateurs | Bastien Dubuisson (Université du Luxembourg / UNamur), Sébastien de Valeriola |
Ce projet vise exploiter la base de données BHLms, qui décrit 7.486 manuscrits médiévaux contenant 16.933 textes hagiographiques latins, c’est-à-dire relatifs aux saints et à leurs reliques.

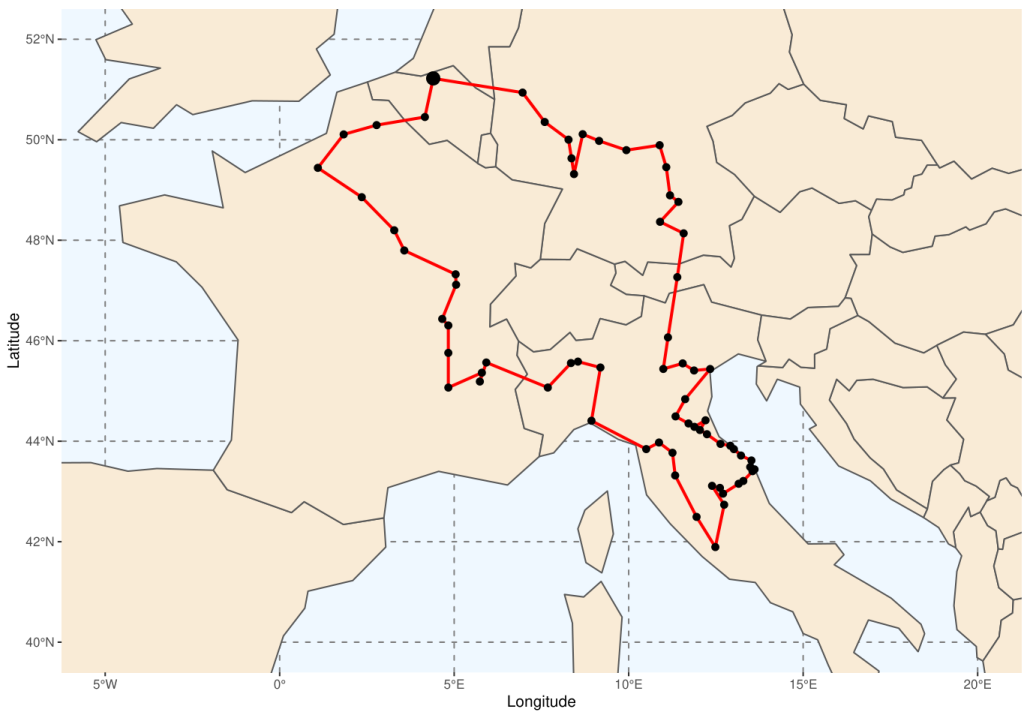
Depuis le milieu du XVIIe siècle, la Société des Bollandistes recueille le plus grand nombre possible de textes de ce type. Pour chaque saint, un dossier a été constitué en rassemblant de nombreuses informations et en confrontant tous les textes auxquels il est possible d’avoir accès. Les Bollandistes ont cherché (et cherchent encore) ces informations dans toute l’Europe. L’exemple du voyage effectué par deux d’entre eux en 1660-1662 à Rome, à l’invitation du pape, pour explorer la bibliothèque du Vatican, est instructif :
À la fin du XIXe siècle, un catalogue général de tous les textes compilés par les Bollandistes a été publié : la Bibliotheca Hagiographica Latina (BHL). La base de données sur laquelle repose ce projet, BHLms, a été créée dans les années 1990 par des chercheurs de l’Université de Namur. Ils ont puisé dans la BHL une mine d’informations qu’ils ont enrichies d’autres sources (caractéristiques des saints, manuscrits, etc.).
Le projet a trois objectifs, correspondant à trois étapes de la recherche.
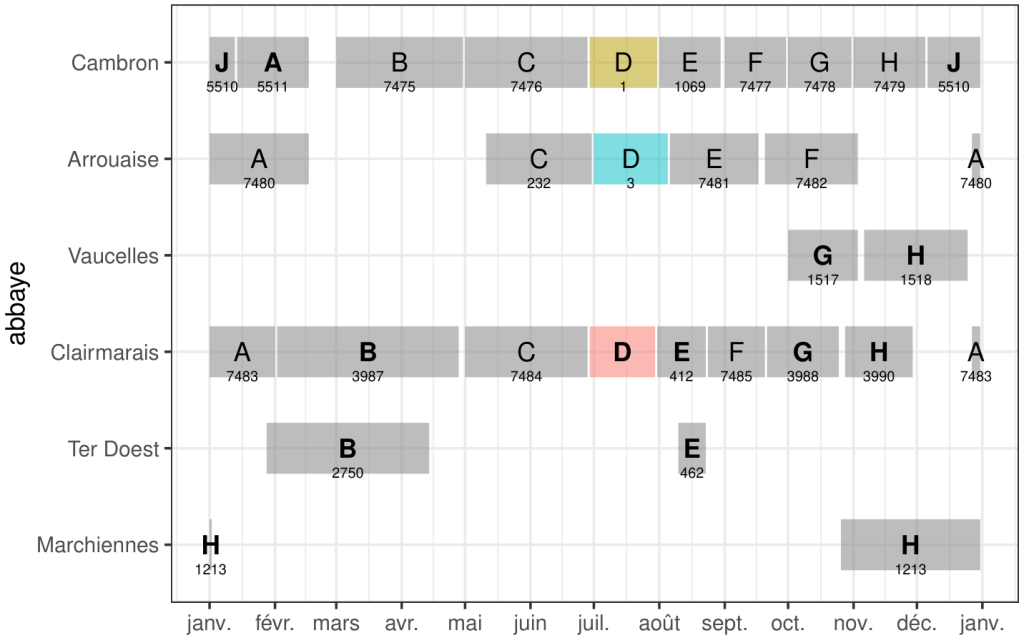
Le premier était de trouver un moyen efficace de visualiser la structure interne des manuscrits hagiographiques. A cette fin, nous avons introduit les Liturgical Feast Sequence Plots, décrits en détail dans un article qui sera publié dans les Actes de la conférence « Old Books and New Technologies », KBR, mai 2021 (eds. Reynhout et Verweij).
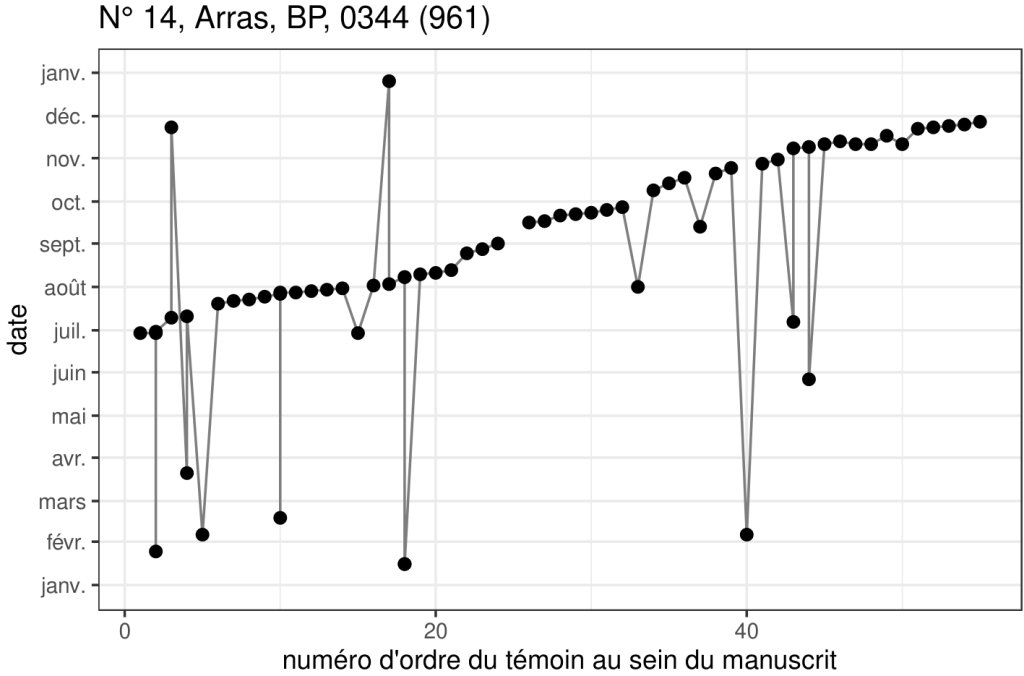
Nous avons ensuite cherché à classer automatiquement ces manuscrits en fonction de leur organisation interne. Dans certains de ces codex, les textes sont organisés selon l’ordre annuel des fêtes liturgiques des saints qu’ils contiennent : on dit qu’ils sont organisés Per Circulum Anni (PCA). En modélisant la courbe formée par les points du tracé de la séquence des fêtes liturgiques, nous avons entraîné un modèle de classification automatique pour classer les manucrits en « PCA » et « non-PCA ».
Les résultats de cette étape ont été compilés dans un article publié dans la revue Digital Scholarship in the Humanities. Ces résultats permettront d’étudier les caractéristiques des manuscrits PCA, de comprendre en détail pourquoi les copistes-compilateurs qui les ont créés ont choisi cette organisation interne.
Le troisième objectif du projet, qui est en cours de réalisation, est d’essayer de reconstituer des familles de manuscrits hagiographiques au contenu similaire, et qui proviennent probablement des mêmes manuscrits parents. Nous avons défini plusieurs notions de distance entre ces manuscrits, basées sur la liste des textes qu’ils contiennent. Cela nous permet d’explorer les similitudes entre les manuscrits, et donc peut-être de découvrir des manuscrits apparentés qui n’ont jamais été rapprochés par l’historiographie traditionnelle.