

| Période | 2024-2025 |
| Promoteurs | Kenneth Bertrams (ULB), Sébastien de Valeriola |
| Bailleur de fonds | ULB, Programme Actions Blanches |
| Collaborateur | Matthieu Pichon |
De 2012 à 2016, le département des bibliothèques et de l’information scientifique de l’ULB (DBIS) a numérisé toutes les thèses de doctorat défendues à l’Université depuis sa création, principalement à des fins de conservation et de diffusion. Plus de 8.000 volumes papier ont été scannés et soumis à un processus de reconnaissance optique des caractères, qui a extrait le contenu d’un peu moins de deux millions de pages. Ces textes numérisés, ajoutés à ceux des 2.500 thèses nativement numériques défendues depuis 2009, forment un ensemble qui est aujourd’hui consultable sur le dépôt institutionnel de l’ULB (DI-fusion), dans la majorité des cas en accès ouvert. Néanmoins, cette importante quantité de documents n’a jamais été considérée comme un corpus cohérent et aucune étude globale n’en a été réalisée jusqu’à présent.
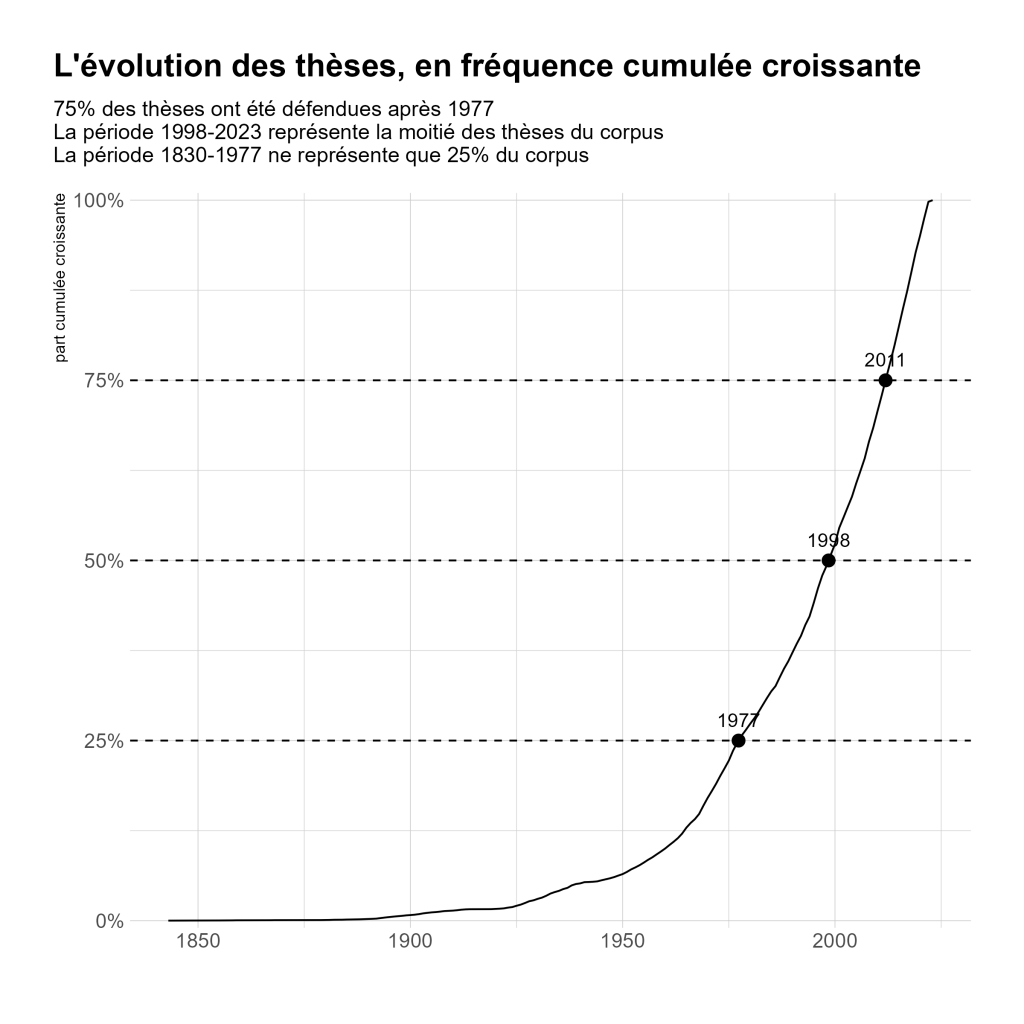
Ce projet de recherche a pour objectif d’initier un ensemble d’analyses quantitatives et qualitatives de ce formidable ensemble de données, qui donne un panorama de l’évolution de la recherche à l’ULB dans toutes les disciplines scientifiques depuis les premières thèses défendues (quelques années après la fondation) jusqu’à aujourd’hui. L’exploitation globale de ce corpus à l’aide d’outils quantitatifs de natures variées (traitement automatique des langues, analyse des réseaux, etc.) constitue une approche novatrice dont les possibilités sont très prometteuses, tant du point de vue de l’histoire des sciences que de l’histoire de l’Université.
Bien que la littérature ait souligné que le nombre de thèses de doctorat réalisées dans une université était un facteur déterminant pour définir le potentiel de recherche de ladite institution, force est de constater que les études empiriques restent rares. Du côté de la scientométrie, quelques travaux mettent en œuvre des thèses de doctorat, mais c’est généralement dans un but méthodologique (pour tester de nouveaux modèles de data mining) ou linguistique (par exemple pour étudier les habitudes de rédaction académiques). De plus, ils utilisent pour ce faire le résumé des thèses plutôt que leur contenu, parce que celui-ci n’est généralement pas disponible à une échelle globale. Dans une autre direction, certains auteurs ont étudié l’évolution de la recherche dans des contextes précis (généralement une discipline) en exploitant les métadonnées des thèses de doctorat, c’est-à-dire leur date, les catégories disciplinaires qui leur sont associées, etc. Ils n’exploitent dans ce cas pas de texte du tout. Du côté de l’histoire des sciences, l’historiographie s’est intéressée à des contextes précis et à haute charge symbolique, par exemple le vaste transfert de connaissances vers les États-Unis provoqué par l’aryanisation des universités allemandes dans les années 1930. Inversement, dans un livre pionnier, l’historien Arnold Thackray a montré que la puissance de l’industrie chimique états-unienne dans le dernier quart du 19ème siècle ne reposait pas uniquement sur des structures de recherche adaptées (les fameux laboratoires centraux de R&D) mais aussi sur une concentration inédite et précoce de chercheurs titulaires d’un doctorat en chimie dont une partie significative s’était spécialisé dans les laboratoires des universités allemandes.
Le projet a trois objectifs principaux.
Le premier est l’obtention d’un ensemble de résultats de recherche généraux à propos du corpus. Le chercheur engagé mettra en place un workflow de prétraitement des données et appliquera au corpus des méthodes de topic modeling, afin de déterminer automatiquement les thèmes qui sont développés dans les thèses7. Il sera alors possible de dresser un panorama global (mais sans doute assez flou) de “l’histoire des idées” à l’ULB.
Le deuxième objectif du projet est la définition de directions de recherche plus précises, qui
pourront être investiguées dans des projets ultérieurs (potentiellement par ou avec d’autres
équipes). Les résultats généraux mentionnés au paragraphe précédent permettront de mieux
comprendre ce qu’il est possible d’obtenir à partir du corpus. Nous serons ainsi en mesure de
formuler de nouvelles questions de recherche, mieux ciblées, tant en termes des sous-corpus
considérés (par exemple les thèses d’une discipline particulière) que des phénomènes à analyser
(évolution du caractère multidisciplinaire de la recherche, évolution de la place des femmes dans
les STEM, reconstitution des écoles de pensée, façon dont les travaux d’autres chercheurs sont
cités, etc.). L’idée étant d’inciter d’autres chercheurs à prendre appui sur le “tremplin” ainsi constitué,
nous organiserons à la fin du projet un événement ouvert à tous les membres de la communauté
universitaire pour présenter les nouvelles pistes de recherche ouvertes par les premiers résultats.

Le troisième objectif du projet sera de tester le potentiel de ces nouvelles directions par l’analyse
d’un cas d’étude particulier qui concerne la chimie et plus particulièrement l’impact d’Ilya Prigogine,
prix Nobel de chimie (1977) et figure tutélaire de la discipline dans la seconde moitié du 20ème siècle.
En s’appuyant sur le corpus des thèses défendues par les “étudiants” de Prigogine ou dirigées par
ses successeurs à l’ULB (physico-chimie non-linéaire), l’exploitation des métadonnées et du corpus
citationnel des thèses sélectionnées nous permettra d’évaluer la cohérence, la portée et les
ramifications de l’”École Prigogine”. En d’autres termes, nous serons en mesure de tester la
robustesse scientométrique de l’impact de Prigogine sur la recherche (doctorale) en chimie à l’ULB
par-delà son empreinte institutionnelle dans les structures de recherche ou son empreinte
“managériale” (comme sa direction des Instituts internationaux de physique et de chimie Solvay de
1959 à 2003, année de son décès).